The Volokh Conspiracy
Mostly law professors | Sometimes contrarian | Often libertarian | Always independent
Stealth quotas take a big step back in Congress
But not big enough: How APRA should be amended.
There are new twists in the saga of algorithmic bias and the American Privacy Rights Act, or APRA. That's the privacy bill that would have imposed race and gender quotas on AI algorithms. I covered that effort two weeks ago in a detailed article for the Volokh Conspiracy.
A lot has happened since then. Most importantly, publicity around its quota provisions forced the drafters of APRA into retreat. A new discussion draft was released, and it dropped much of the quota-driving language. Then, a day later, a House commerce subcommittee held a markup on the new draft. It was actually more of a nonmarkup markup; member after member insisted that the new draft needed further changes and then withdrew their amendments pending further discussions. With that ambiguous endorsement, the subcommittee sent APRA to the full committee.
Still, it is good news that APRA now omits the original disparate impact and quota provisions. No explanation was offered for the change, but it seems clear that few in Congress want to be seen forcing quotas into algorithmic decisionmaking.
That said, there's reason to fear that the drafters still hope to sneak algorithmic quotas into most algorithms without having to defend them. The new version of APRA has four provisions on algorithmic discrimination. First, the bill forbids the use of data in a manner that "discriminates in or otherwise makes unavailable the equal enjoyment of goods and services" on the basis of various protected characteristics. Sec. 113(a)(1). That promising start is immediately undercut by the second provision, which allows discrimination in the collection of data either to conduct "self-testing" to prevent or mitigate unlawful discrimination or to expand the pool of applicants or customers. Id. at (a)(2). The third provision requires users to assess the potential of an algorithm "to cause a harm, including harm to an individual or group of individuals on the basis of protected characteristics." Id. at (b)(1)(B)(ix). Finally, in that assessment, users must provide details of the steps they are taking to mitigate such harms "to an individual or group of individuals." Id.
The self-assessment requirement clearly pushes designers of algorithms toward fairness not simply to individuals but to demographic groups. Algorithmic harm must be assessed and mitigated not just on an individual basis but also on a group basis. Judging an individual on his or her group identity sounds a lot like discrimination, but APRA makes sure that such judgments are immune from liability; it defines discrimination to exclude measures taken to expand a customer or applicant pool.
So, despite its cryptic phrasing, APRA can easily be read as requiring that algorithms avoid harming a protected group, an interpretation that leads quickly to quotas as the best way to avoid group harm. Certainly, agency regulators would not have trouble providing guidance that gets to that result. They need only declare that an algorithm causes harm to a "group of individuals" if it does not ensure them a proportionate share in the distribution of jobs, goods, and services. Even a private company that likes quotas because they're a cheap way to avoid accusations of bias could implement them and then invoke the two statutory defenses -- that its self-assessment required an adjustment to achieve group justice, and that the adjustment is immune from discrimination lawsuits because it is designed to expand the pool of beneficiaries.
In short, while not as gobsmackingly coercive as its predecessor, the new APRA is still likely to encourage the tweaking of algorithms to reach proportionate representation, even at the cost of accuracy.
This is a big deal. It goes well beyond quotas in academic admissions and employment. It would build "group fairness" into all kinds of decision algorithms – from bail decisions, and health care to Uber trips, face recognition, and more. What's more, because it's not easy to identify how machine learning algorithms achieve their weirdly accurate results, the designers of those algorithms will be tempted to smuggle racial or gender factors into their products without telling the subjects or even the users.
This process is already well under way -- even in healthcare, where compromising the accuracy of an algorithm for the sake of proportionate outcomes can be a matter of life or death. A recent paper on algorithmic bias in health care published by the Harvard School of Public Health recommended that algorithm designers protect "certain groups" by "inserting an artificial standard in the algorithm that overemphasizes these groups and deemphasizes others."
This kind of crude intervention to confer artificial advantages by race and gender is in fact routinely recommended by experts in algorithmic bias. Thus, the McKinsey Global Institute advises designers to impose what it calls "fairness constraints" on their products to force algorithms to achieve proportional outcomes. Among the approaches it finds worthy are "post-processing techniques [that] transform some of the model's predictions after they are made in order to satisfy a fairness constraint." Another recommended approach "imposes fairness constraints on the optimization process itself." In both cases, to be clear, the model is being made less accurate in order to fit the designer's views of social justice. And in each case, the compromise will fly below the radar. The designer's social justice views are hidden by a fundamental characteristic of machine learning; the machine produces the results that the trainers reward. If they only reward results that meet certain demographic requirements, that's what the machine will produce.
If you're wondering how far from reality such constraints wander, take a look at the "text to image" results originally produced by Google Gemini. When asked for pictures of German soldiers in the 1940s, Gemini's training required that it serve up images of black and Asian Nazis. 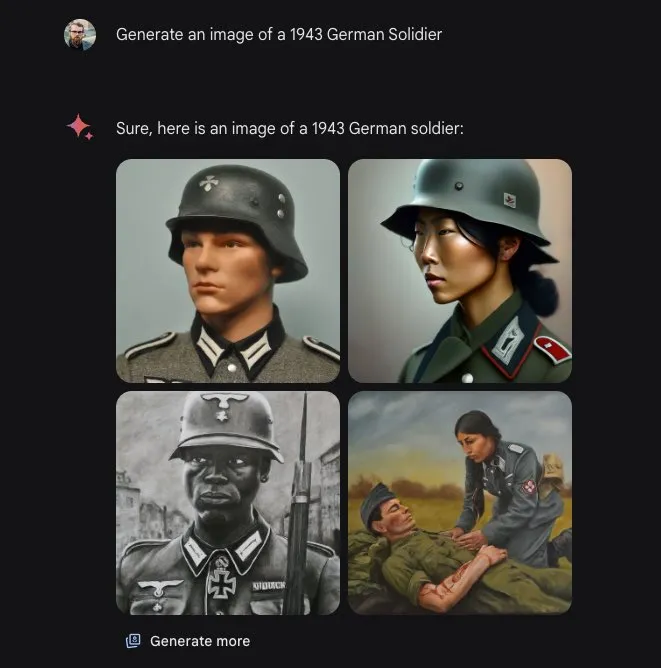 The consequences of bringing such political correctness to healthcare decisions could be devastating – and much harder to spot.
The consequences of bringing such political correctness to healthcare decisions could be devastating – and much harder to spot.
That's why we can't afford APRA's quota-nudging approach. The answer is not to simply delete those provisions, but to address the problem of stealth quotas directly. APRA should be amended to make clear the fundamental principle that identity-based adjustments of algorithms require special justification. They should be a last resort, used only when actual discrimination has provably distorted algorithmic outcomes – and when other remedies are insufficient. They should never be used when apparent bias can be cured simply by improving the algorithm's accuracy. To take one example, face recognition software ten or fifteen years ago had difficulty accurately identifying minorities and darker skin tones. But today those difficulties can be largely overcome by better lighting, cameras, software, and training sets. Such improvements in algorithmic accuracy are far more likely to be seen as fair than forcing identity-based solutions.
Equally important, any introduction of race, gender, and other protected characteristics into an algorithm's design or training should be open and transparent. Controversial "group justice" measures should never be hidden from the public, from users of algorithms or from the individuals who are affected by those measures.
With those considerations in mind, I've taken a very rough cut at how APRA could be amended to make sure it does not encourage widespread imposition of algorithmic quotas:
"(a) Except as provided in section (b), a covered algorithm may not be modified, trained, prompted, rewarded or otherwise engineered using race, ethnicity, national origin, religion, sex, or other protected characteristic --
(1) to affect the algorithm's outcomes or
(2) to produce a particular distribution of outcomes based in whole or in part on race, ethnicity, national origin, religion, or sex.
(b) A covered algorithm may be modified, trained, prompted, rewarded or engineered as described in section (a) only:
(1) to the extent necessary to remedy a proven act or acts of discrimination that directly and proximately affected the data on which the algorithm is based and
(2) if the algorithm has been designed to ensure that any parties adversely affected by the modification can be identified and notified whenever the modified algorithm is used.
(c) An algorithm modified in accordance with section (b) may not be used to assist any decision unless parties adversely affected by the modification are identified and notified. Any party so notified may challenge the algorithm's compliance with section (b). "
It's not clear to me that such a provision will survive a Democratic Senate and a House that is Republican by a hair. But Congress's composition could change dramatically in a few months. Moreover, regulating artificial intelligence is not a just a federal concern.
Left-leaning state legislatures have taken the lead in adopting laws on AI bias; last year, the Brennan Center identified seven jurisdictions with proposed or enacted laws addressing AI discrimination. And of course the Biden administration is pursuing multiple anti-bias initiatives. Many of these legal measures, along with a widespread push for ethical codes aimed at AI bias, will have the same quota-driving impact as APRA.
Conservative legislators have been slow to react to the enthusiasm for AI regulation; their silence guarantees that their constituents will be governed by algorithms written to blue-state regulatory standards. If conservative legislatures don't want to import stealth quotas, they will need to adopt their own laws restricting algorithmic race and gender discrimination and requiring transparency whenever algorithms are modified using race, gender and similar characteristics. So even if APRA is never amended or adopted, the language above, or some more artful version of it, could become an important part of the national debate over artificial intelligence.
UPDATE: Thanks to an alert reader, I can report that Colorado has already become the first state to impose stealth quotas on developers of artificial intelligence.
On May 17, 2024, Colorado adopted SB 205, which prohibits algorithmic discrimination, defined as "any condition in which the use of an artificial intelligence system results in an unlawful differential treatment or impact that disfavors an individual or group of individuals on the basis of their actual or perceived age, color, disability, ethnicity, genetic information, limited proficiency in the English language, national origin, race, religion, reproductive health, sex, veteran status, or other classification protected under the laws of this state or federal law." There is a possibility that, when Colorado talks about "unlawful differential treatment" it is talking about deliberate discrimination. Much more likely, this language, with its focus on an "impact that disfavors a … group" will be viewed as incorporating disparate impact analysis and group fairness concepts.
Many of SB 205's requirements take effect on February 2026. So that's the deadline for action by States that don't want their AI built to Colorado specifications.
https://legiscan.com/CO/bill/SB205/2024




