The Volokh Conspiracy
Mostly law professors | Sometimes contrarian | Often libertarian | Always independent
Can GPT Pass the Multistate Bar Exam?
A new paper by Mike Bommarito and Dan Katz finds that AI will likely "pass the MBE component of the Bar Exam in the near future"
AI tools like ChatGPT can generate essays. And, as my little thought experiment demonstrated, many people cannot distinguish the words that I put together from the words assembled by ChatGPT. (I assure you, this is Josh typing--or is it?) But did you know that similar technology can also answer multiple choice questions?
My frequent co-authors, Mike Bommarito and Dan Katz utilized a different software tool from OpenAI, known as GPT-3.5, to answer the multiple choice questions on the Multistate Bar Examination (MBE). If there are four choices, the "baseline guessing rate" would be 25%. With no specific training, GPT scored an overall accuracy rate of 50.3%. That's better than what many law school graduates can achieve. And in particular, GPT reached the average passing rate for two topics: Evidence and Torts. (I'll let Evidence or Torts scholars speculate about why those topics may be easier for AI.) Here is a summary of the results from their paper:
The table and figure clearly show that GPT is not yet passing the overall multiple choice exam. However, GPT is significantly exceeding the baseline random chance rate of 25%. Furthermore, GPT has reached the average passing rate for at least two categories, Evidence and Torts. On average across all categories, GPT is trailing human test-takers by approximately 17%. In the case of Evidence, Torts, and Civil Procedure, this gap is negligible or in the single digits; at 1.5 times the standard error of the mean across our test runs, GPT is already at parity with humans for Evidence questions. However, for the remaining categories of Constitutional Law, Real Property, Contracts, and Criminal Law, the gap is much more material, rising as high as 36% in the case of Criminal Law.
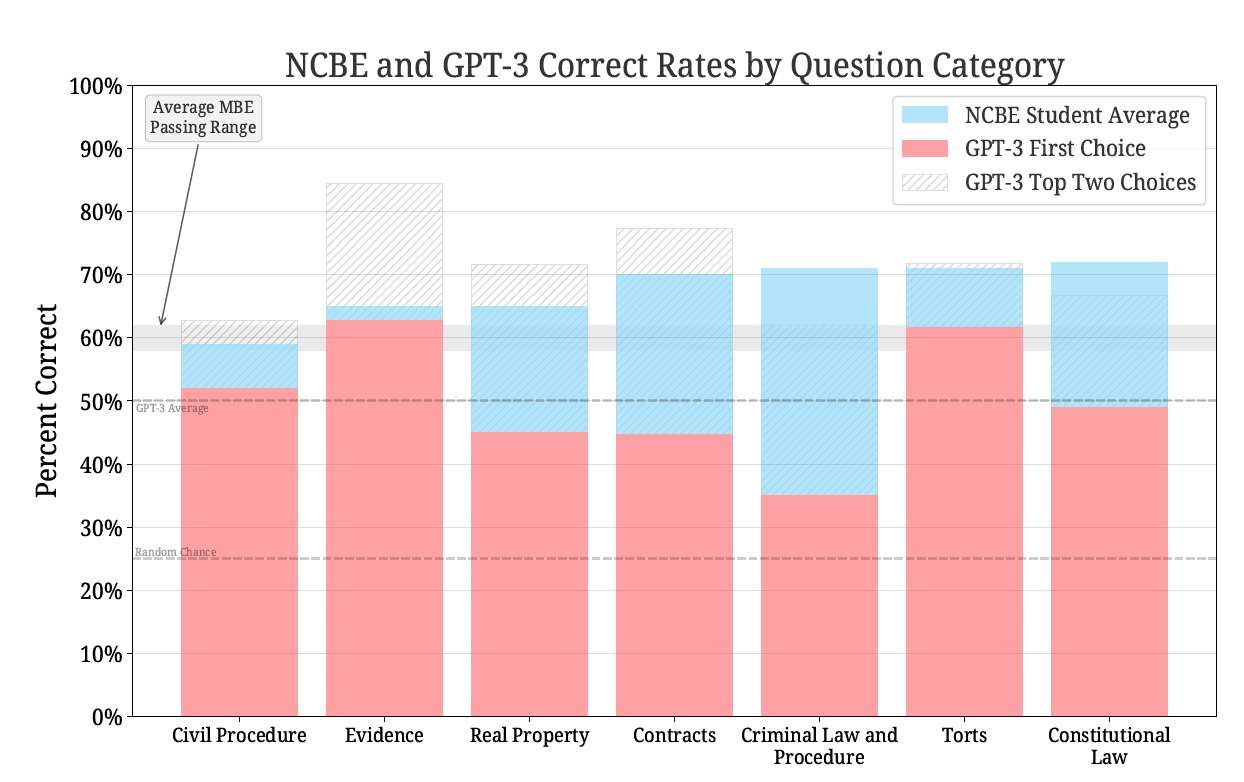
In this graphic, the blue area indicates the NCBE student average, and the red area indicates the top choice generated by GPT. As you can see, for Evidence in particular, the machine is just about ready to beat man. Objection overruled. Resistance is futile.
The authors, who are leaders in this field, were extremely surprised by their results. They expect a similar tool to be able to pass the MBE somewhere between 18 months from now, and tomorrow:
Overall, we find that GPT-3.5 significantly exceeds our expectations for performance on this task. Despite thousands of hours on related tasks over the last two decades between the authors, we did not expect GPT-3.5 to demonstrate such proficiency in a zero-shot settings with minimal modeling and optimization effort. While our ability to interpret how or why GPT-3.5 chooses between candidate answers is limited by understanding of LLMs and the proprietary nature of GPT, the history of similar problems strongly suggests that an LLM may soon pass the Bar. Based on anecdotal evidence related to GPT-4 and LAION's Bloom family of models, it is quite possible that this will occur within the next 0-18 months.
Worried yet?




