American Pessimism: Only 6 Percent Think the World Is Getting Better
Over the past century, the prospects and circumstances of most of humanity have spectacularly improved

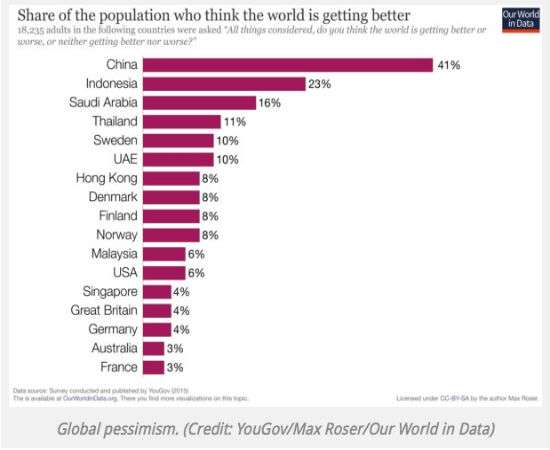
Over at the invaluable American Council on Science and Health, ASCH senior biomedical fellow Alex Berezow reports the depressing news that only 6 percent of Americans believe that, all things considered, the world is getting better. The most optimistic people are the Chinese; 41 percent think that future is bright. Berezow is citing data collated by Oxford economist Max Roser and shared at recent conference of "ecomodernists" at the Breakthrough Institute. Why are so many people so pessimistic? Berezow reports that Roser suggested (1) they forget how bad things were and (2) they don't know how much progress is being made. As Berezow notes:
The fact is that bad news sells. Good news does not. Proclaiming widespread misery is how politicians get elected (and how most environmentalists get funded), and giving coverage to mass shooters is how newspapers are sold. Giving people a balanced perspective, which often includes a dose of good news, rarely excites anybody.*
Last year, in my column, "The End Is Nigh," I reported similar dispiriting data from the Futures survey:
A majority of people—54 percent—surveyed in the United States, Canada, Australia, and the United Kingdom believe there's a risk of 50 percent or more that our way of life will end within the next 100 years. Even worse, some 25 percent of respondents in the same poll believe it that likely that we'll go extinct in the next century. Americans were the most pessimistic, giving those gloomy answers 57 percent and 30 percent of the time, respectively. And younger respondents tend to be more pessimistic about the future than older ones. …
This pervasive pessimism about the human prospect flies in the face of a plain set of facts: Over the past century, the prospects and circumstances of most of humanity have spectacularly improved. Depending on how you calculate it, world per capita GDP has increased between 5-fold and 10-fold since 1900. Average life expectancy has more than doubled in the same period, and we live in the most peaceful time in history.
I hold modern intellectuals, fellow members of the scribbling classes, responsible for the miasma of cultural pessimism that has engulfed so many rich societies. I reiterate:
In 1982, the brilliant futurist Herman Kahn published The Coming Boom, in which he pleaded for the reestablishment of "an ideology of progress." Kahn warned:
Two out of three Americans polled in recent years believe that their grandchildren will not live as well as they do, i.e., they tend to believe the vision of the future that is taught in our school system. Almost every child is told that we are running out of resources; that we are robbing future generations when we use these scarce, irreplaceable, or nonrenewable resources in silly, frivolous and wasteful ways; that we are callously polluting the environment beyond control; that we are recklessly destroying the ecology beyond repair; that we are knowingly distributing foods which give people cancer and other ailments but continue to do so in order to make a profit.
It would be hard to describe a more unhealthy, immoral, and disastrous educational context, every element of which is either largely incorrect, misleading, overstated, or just plain wrong. What the school system describes, and what so many Americans believe, is a prescription for low morale, higher prices and greater (and unnecessary) regulations.
Three decades later, large swaths of the Western intellectual classes still preach an apocalyptic anti-progress ideology. As the Futures survey shows, corrosive pessimism has clearly trickled down and is demoralizing many citizens. Such cultural gloom is a significant drag on scientific, technological and policy innovation. Overcoming that pervasive pessimism and restoring the belief in human progress is one of the most important philosophical and political projects for the 21st century.
Still true.
*Compare the sales of my realistic new book, The End of Doom, to the sales of doomster Paul Ehrlich's apocalyptic tomes. Well, I, at least, have the satisfaction of being right.