A recent Volokh Consiracy post noted the shift in our nation's history from using "United States" as a plural noun to using it as a singular noun, arguably reflecting the increasing tendency of Americans to identify first with their country and secondarily with their state in the post-Civil War era. The post cited two attempts to understand the historical shift from "the United States are" to "the United States is," one by Mark Liberman and one by Minor Myers, who respectively relied on two corpora (or collection of texts): Pennsylvania newspapers from 1831-1877 and U.S. Supreme Court opinions from 1790-1919. These two corpora tell us something, but arguably little about general historical American usage of "United States."
That's because one can only generalize to (or make inferences about) a particular speech community if one is analyzing a corpus that represents that speech community. Thus, a corpus of speeches of 19th Century American presidents will not help us make inferences about the language usage of 21st Century Ukrainian teenagers. This principle is clearly understood in survey opinion polling. Few would believe an opinion poll of Pennsylvanians in the mid-1800s or of Supreme Court justices would accurately portray American opinion overall during the same time periods. In other words, ask the right question of the wrong corpus and get an irrelevant answer. (For more on this, see scholarship here and here.)
The best corpus for investigating the question here is Mark Davies's Corpus of Historical American English (or COHA). It is the only large, structured historical corpus of American English that covers most of our country's existence: 1810-2009 (there will soon be a Corpus of Founding-Era American English that will cover 1760-1799, created by BYU's Law School). As a structured corpus, COHA contains texts from fiction, popular magazines, newspapers, and non-fiction books, with about the same number of words representing each decade, though COHA reports both raw frequencies and words per million to compensate for early decades that are represented by fewer words. In short, we can more confidently extrapolate patterns found in COHA to the American people generally during the same time period.
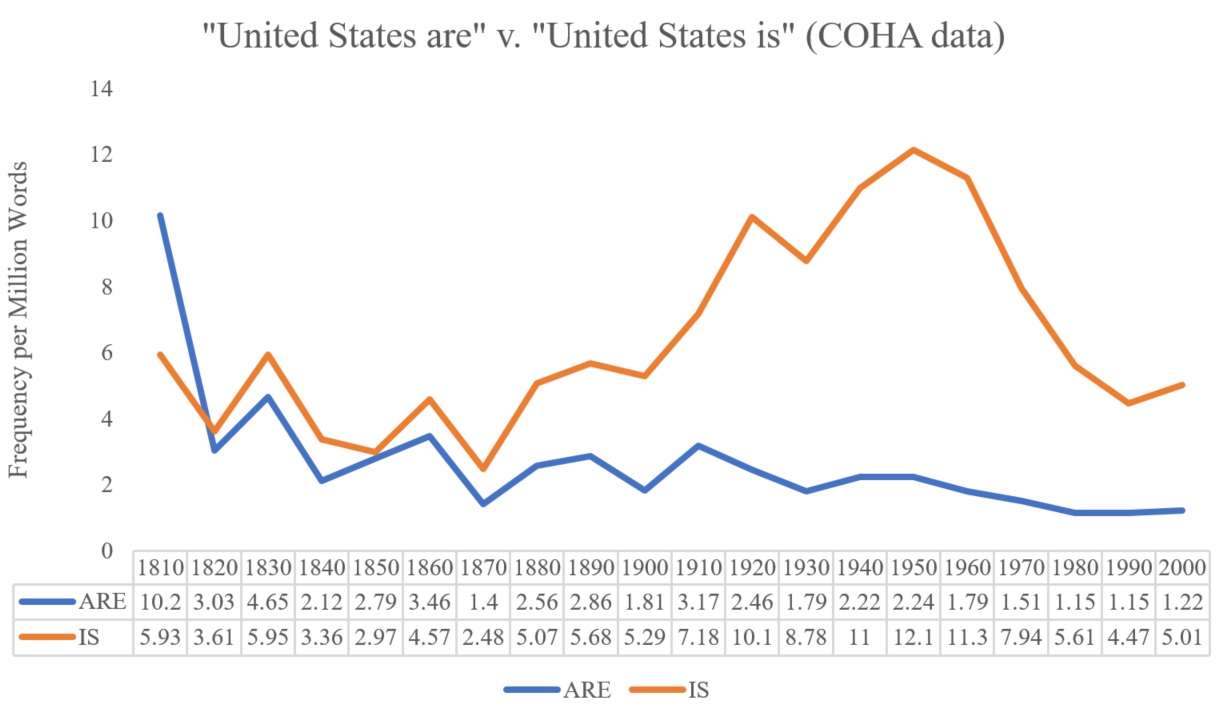
Searching for "United States is" and "United States are" in COHA, we get the following results (combined into one graph via Excel):
There does not appear to be a sharp decrease in the use of plural version following the Civil War—usage was already slightly declining and generally that trend continued. As for the singular noun version of "United States," after the Civil war there is an immediate drop in the 1870s, followed by a fairly large increase as it becomes the preferred version. These are somewhat different results than the ones found in looking at much narrower (Pennsylvania newspapers) or specialized (Supreme Court opinions) corpora noted above. And the findings are certainly more generalizable to the United States as a whole.
With a corpus like COHA, one could further delve into genre-specific patterns: for example, do we see differences in non-fiction books compared to popular magazines? And one can dive even deeper to see to what degree context matters for choosing "is" versus "are" after "United States." Similarly, one could do a search of the words that most frequently co-occur (collocates) with "United States is" compared to "United States are." Thus, a well-made corpus can help answer more nuanced questions that a bare-bones collection of texts cannot.
Corpus linguistics is relatively new—roughly a half-century old in linguistics, and just now beginning to be applied in other contexts, including law (see scholarship here for statutory interpretation, here and here for constitutional interpretation, and here for criminal law). But corpus linguistics is everywhere, if hidden: from the suggestion for the next word your smart phone gives you when writing a text to the definitions in modern dictionaries. And as big-data has revolutionized fields as diverse as sports, medicine, and political campaigns, corpus linguistics has the potential to improve answers to linguistic-related questions we've long been asking and long been answering with less accurate tools.
(Unsurprisingly, the views expressed here are Phillips', and not necessarily those of Becket or its clients.)